Cieľom tohto článku je zosumarizovať postupy, ktoré som implementovala pri testovaní ETL procesov a s ktorými som sa stretla v rámci big data
Úvod do big data a ETL #
Veľké dáta (ďalej big data) sú charakterizované troma V:
- volume - veľký objem dát,
- velocity - rýchlosť s akou sú produkované (gigabajty nových dát denne),
- variety - dáta prichádzajú z rôznych zdrojov a v rôznej forme.
Sú to také veľké súbory dát, že ich nie je možné uchovávať, spravovať a spracovávať bežne používanými softvérovými prostriedkami v rozumnom čase.
Úlohou dátových inžinierov je spracovanie big data a ich príprava do požadovanej podoby pre ďalších používateľov dát - spravidla dátových analytikov, dátových vedcov.
Jeden z procesov, ktorým sa to deje, sa nazýva ETL (extract-transform-load).
V prvej fáze ETL sa dáta extrahujú zo zdrojov - sťahujú sa z FTP serverov, cloudových úložísk, dotazujú sa cez REST API a pod. Surové dáta môžu mať rôznu štruktúru - tabuľky v relačných databázach, záznamy v NoSQL databázach, súbory formátu CSV, XML, JSON atď.
Počas fázy transformácie sa dáta upravujú podľa požadovaných pravidiel, filtrujú, očisťujú, spájajú s inými dátami, prevádzajú sa nad nimi agregácie alebo iné výpočty. Tieto medzivýsledky sa držia v oblasti staged.
V záverečnej fáze sa finálne dáta publikujú na dohodnutom mieste, spravidla v dátovom sklade (data warehouse - DWH), kde ich priamo alebo cez connectory vedia používatelia dotazovať, pracovať s nimi, využiť ako podklad pre analytické a BI (business intelligence) nástroje.
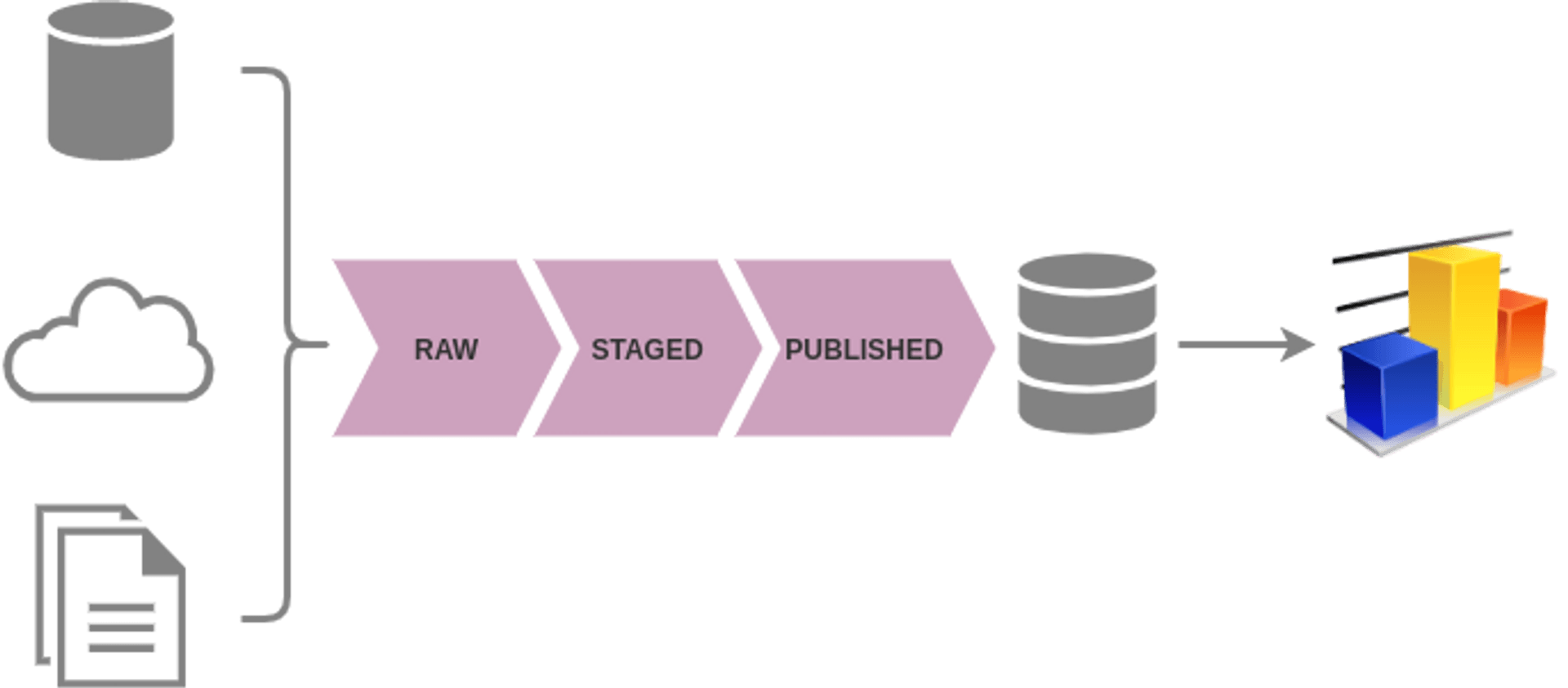
Novším prístupom je ELT (extract-load-transform) proces, pri ktorom sa surové dáta nahrajú na cieľový systém a transformácie sa vykonávajú až tam, napr. s pomocou nástroja dbt.
ETL procesy môžu prebiehať:
- dávkovo - batch processing, kedy sú spúšťané periodicky, riadené orchestrátorom
- ako streaming, kedy sú dáta spracúvané v reálnom čase ako prichádzajú do systému
Na našom projekte sme uplatňovali batch processing a ako orchestrátor pre definovanie workflowow a plánovanie ich behov sme používali Oozie a neskôr aj Airflow. Ukážka ako taký workflow môže vyzerať (zdroj obrázka):
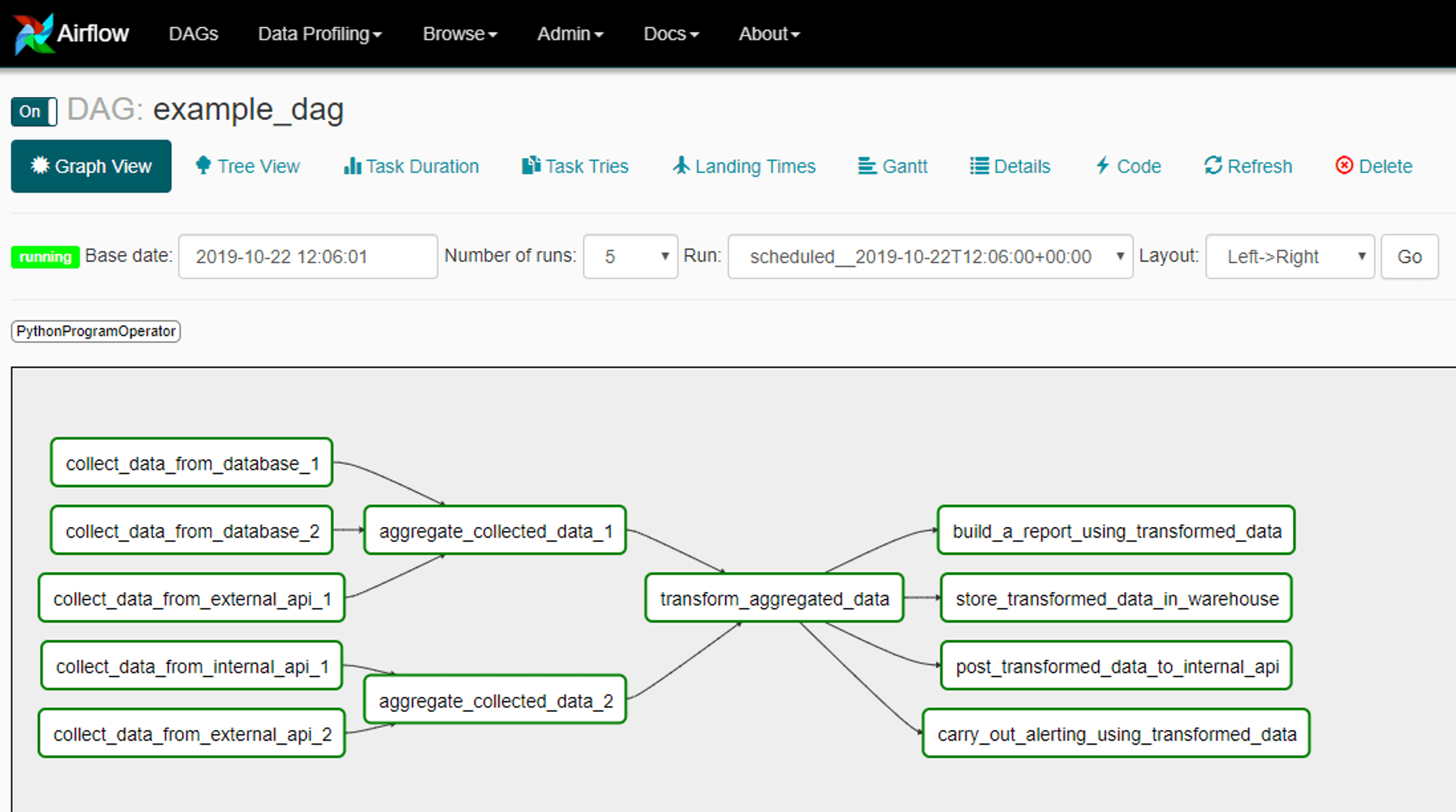
Na samotné spracúvanie dát sme používali Apache Spark, o ktorom som písala v tomto príspevku. Pre predstavu na akom HW Spark a Hadoop bežal, išlo o Oracle BDA/HDFS cluster o 12 uzloch (každý s procesorom Intel XEON), ktorý dokopy disponoval 1 TB RAM a 900 TB HDD.
Testovanie a zabezpečenie kvality ETL procesov bolo náplňou mojej práce v DAZN. Keď som nastúpila, big data boli pre mňa nové a netušila som, ako to budem testovať. Online zdrojov k téme testovania dát je poskromne aj teraz a keď som začínala, nachádzala som len odkazy na platené nástroje, ale máločo o konkrétnych metódach. Názvy testov v nasledujúcom texte sú interné označenia, nejde o odbornú terminológiu.
Dátové E2E testy #
Prvým krokom pri zavedení automatizovaného testovania jednotlivých ETL procesov bolo vytvorenie niečoho ako E2E testov nad fixnými dátami. V prostredí som vytvorila osobitné priečinky, kde som si pripravila súbory s testovacími dátami po vzore reálnych. Malú vzorku, tak aby som mala kontrolu nad tým, čo v nej je a čo sa s ňou deje. Pripravila som dáta pre rôzne testovacie prípady, tzv. happy path aj okrajové prípady, či sa do výsledku dostávajú skutočne tie dáta, ktoré majú.
Nad týmito dátami som púšťala workflowy, ktoré ich spracovali a na konci sa výsledné dáta porovnali s očakávaným výsledkom. Automatizovaný test alebo pomocný skript na záver všetky výsledné dáta aj medzivýsledky ETL procesu zmazal a pripravil prostredie na ďalší beh celého testovacieho workflowu.
Ak bol ETL proces jednoduchý a napr. zabezpečoval len, aby sa v published držala najnovšia verzia záznamu, automatizované testy bežali na produkčných dátach a porovnávali vstupné dáta s výstupnými.
E2E testy pomohli vyriešiť záhadný bug - mala som podozrenie, že občas majú niektoré záznamy isté hodnoty dvojnásobné ako by mali byť, ale nevedeli sme kedy a prečo sa tak deje. Až keď som sa dostala k nasimulovaniu celého procesu a dát, tak som zistila, že v špecifickom prípade, keď dáta spadali do dvoch kategórií, tieto sa započítali dvakrát.
Testy konzistentnosti #
Ďalšou skupinou automatizovaných testov boli testy, ktoré zisťovali, či sú produkčné dáta konzistentné z hľadiska logiky domény. Príklad z digitálneho marketingu: počet kliknutí na reklamu musí byť menší ako počet videní a ten zas menší ako počet požiadaviek o reklamu odoslaných serveru.
Testy konzistentnosti sme vo veľkom využili pri implementácii produktu single customer view v grafovej databáze Neo4j. Grafová databáza je koncept umožňujúci jednoducho modelovať vzťahy reálne existujúce v doméne. Ukážka vzťahov medzi rôznymi uzlami a dopytovacieho jazyka Cypher:
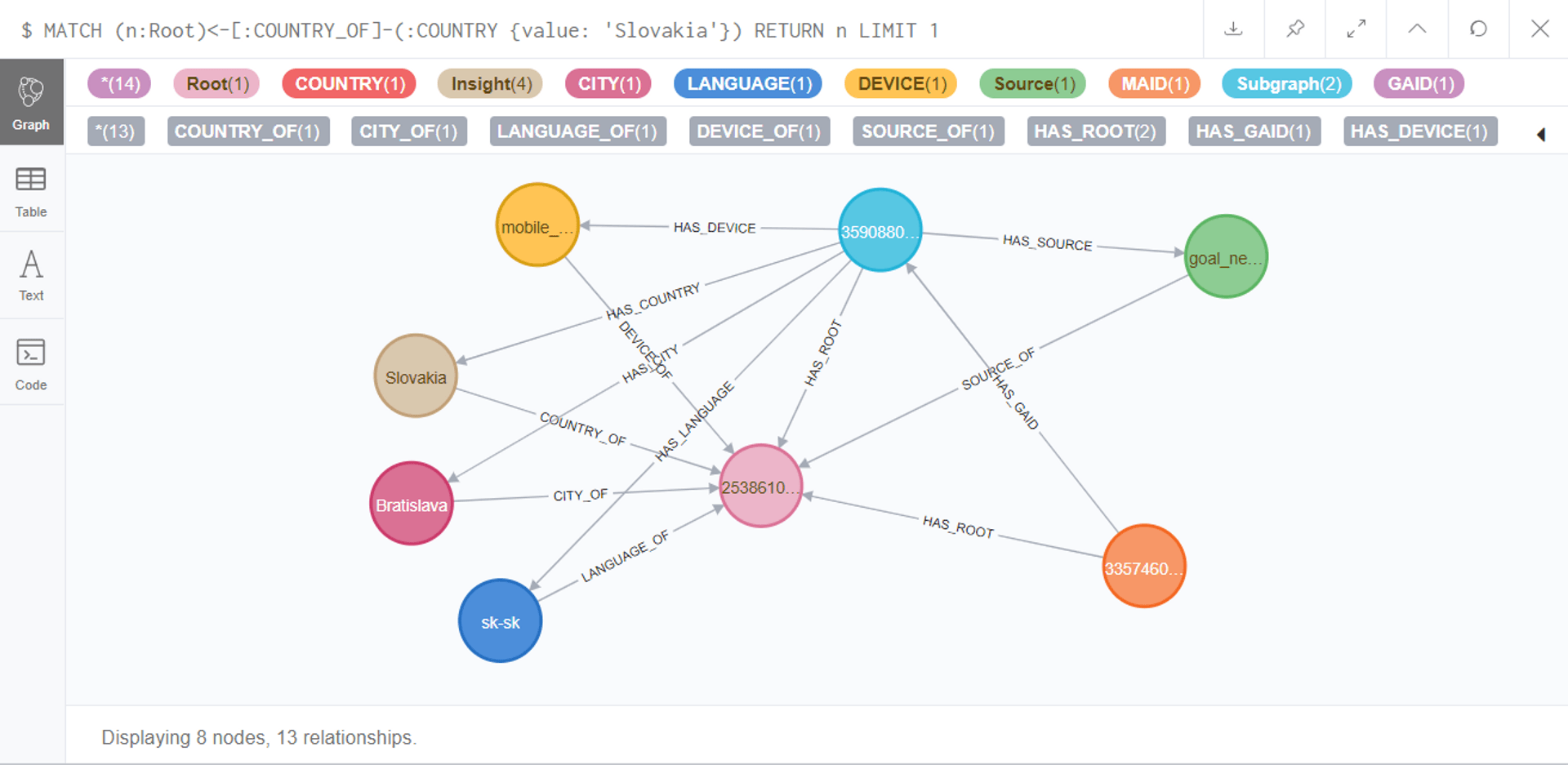
Testy overovali, či skutočný stav zodpovedá navrhnutému dátovému modelu grafu - či sú správne vlastnosti uzlov a vzťahov, či nie sú vzťahy duplicitné, či sa v grafe nenachádzajú entity po TTL (time-to-live). Testy konzistentnosti nám pomohli nájsť chyby v implementácii grafu, identifikovať veci, ktoré sme doposiaľ pri implementácii neošetrili a tiež skryté zlyhania workflowov.
Monitoring #
Tretím pilierom, ktorý nám veľmi pomohol odhaľovať problémy a anomálie a zvýšiť dôveru vo fungovanie našich ETL procesov, bolo nastavenie monitoringu metrík týkajúcich sa dát a samotných ETL procesov. Použili sme na to Kibanu od Elasticu (existuje veľa alternatív, napr. open-source Grafana). Vytypovali sme metriky, ktoré sa opäť periodicky spúšťali ako Spark aplikácie (metriky týkajúce sa súborov na HDFS a tabuliek v Hive), Scala aplikácie (metriky týkajúce sa grafu v Neo4j a workflowov v Oozie) alebo bash skripty (metriky týkajúce sa tabuliek v BigQuery) a zaznamenávali hodnoty v logoch pre Kibanu.
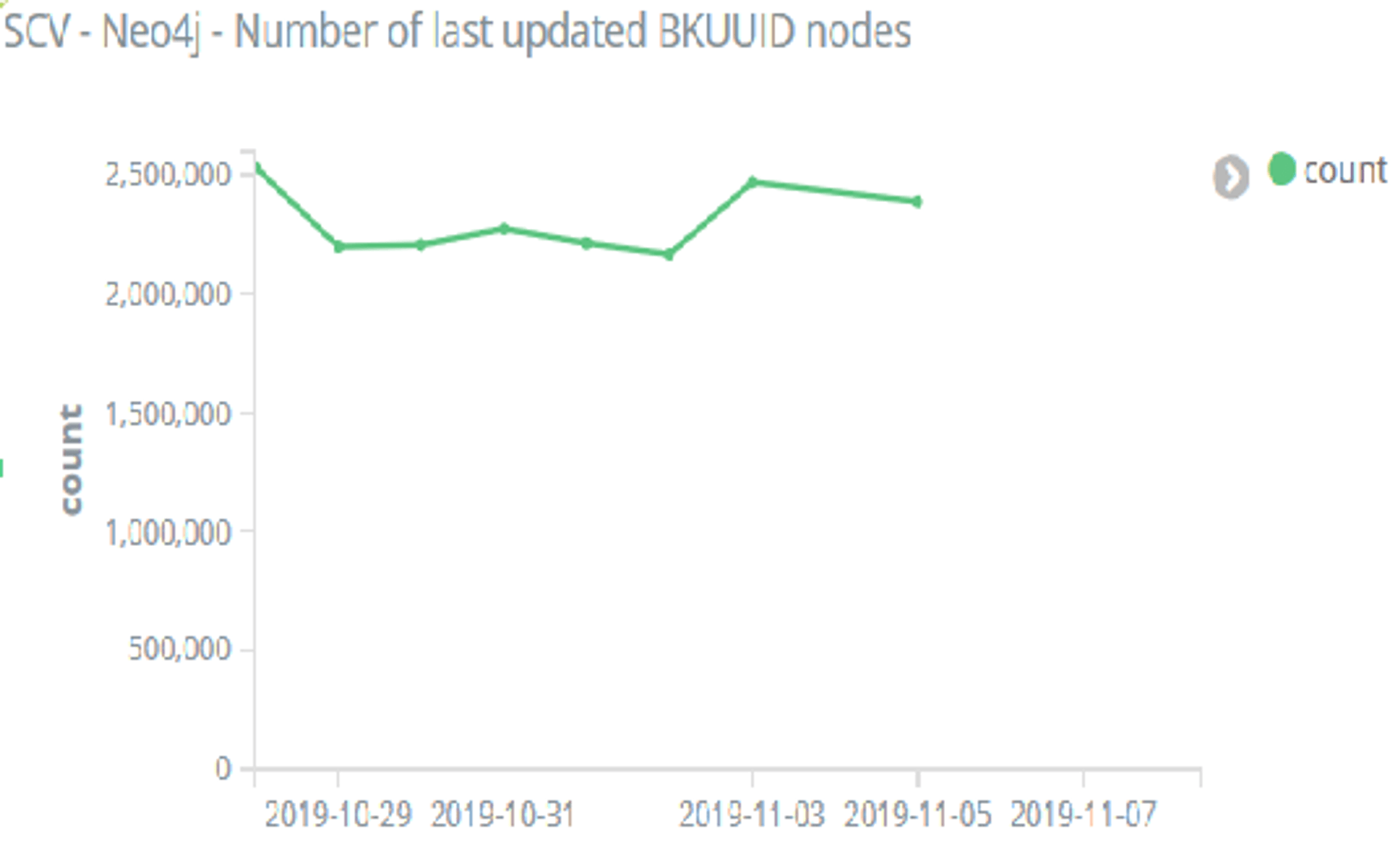
Išlo napr. o počet modifikovaných uzlov v daný deň (na obrázku vyššie); veľkosť surových dát, ktoré sa stiahli daný deň; sumy záznamov vo výsledných dátach; dĺžku trvania ETL procesu.
Do Kibany reportovali výsledky aj testy, ktoré kontrolovali, či sú prítomné dáta z každej hodiny dňa, či boli všetky surové dáta spracované, či všetky staged dáta boli publikované a či sa na HDFS nenachádzajú staré súbory, ktoré mali byť vymazané po uplynutí doby retencie dát. Nastavila som alerty, aby sme boli o takýchto udalostiach notifikovaní emailom.
Kvalita dát, katalóg dát a spol. #
Testy boli hotové - vyžadovali len údržbu, monitoring fičal, tak som začala rešeršovať, aké vychytávky by sa ešte dali zaradiť a tým dvihnúť kvalitu našich ETL procesov na ešte vyššiu úroveň. Bohužiaľ, k skúsenostiam s nasledovnými nástrojmi z prvej ruky som sa už nedostala, keďže priority na projekte sa presunuli smerom od big data a neskôr som zmenila pôsobisko.
Profilovanie dát je proces skúmania zdrojových dát a porozumenia ich štruktúre, obsahu a vzájomných vzťahov s cieľom identifikovania potenciálu pre dátové projekty. Výsledky testovania, monitoringu a profilovania a ich sprievodné vizualizácie môžu pomôcť identifikovať vzory v dátach a príležitosti prepojenia datasetov, značkovania a pridania metadát s cieľom lepšie identifikovať a kategorizovať informácie v organizácii.
Nástroje na kvalitu dát umožňujú analýzu datasetu, validáciu dát, profilovanie dát, odhalenie nevalidných (napr. duplicitné záznamy, hodnoty v stĺpci nezodpovedajúce dátovému typu alebo rozsahu hodnôt, v akom by mali byť), chýbajúcich alebo neobvyklých dát. Nastavujú sa prahy akceptovaných parametrov pre dáta s dobrou kvalitou, oproti ktorým sa dáta testujú a pravidelne kontrolujú, či spĺňajú vopred definované pravidlá a štandardy kvality. Zámerom bolo zapojiť takéto testy do workflowu a zastaviť ďalšie spracovávanie datasetu, ak by obsahoval zlé dáta a tým zabrániť zavedeniu zlých dát do published.
Pre tieto účely som našla knižnicu Great Expectations, nemohli sme ju však použiť kvôli nekompatibilnej verzii Pythonu na našom clusteri. Great Expectations umožňuje tiež automatickú dokumentáciu dát. Až neskôr som objavila alternatívy pre Scalu ako Deequ, DDQ, DataFrame Rules Engine a Apache Griffin. Soda SQL operuje nad dátami prístupnými SQL, podporuje Amazon Redshift, Apache Hive a Spark, Snowflake a niekoľko DB a pravidlá sa definujú v YAML formáte. Umožňuje aj používanie vlastných metrík.
Zaujímavo sa javili aj nástroje na vytvorenie katalógu dát Amundsen a na pôvod dát a vizualizáciu procesov Apache Spline. Katalóg dát slúži ako organizovaný inventár dát pre dátových inžinierov a používateľov dát, kde môžu na jednom mieste vyhľadávať dáta vhodné pre svoje potreby.
Pomocou môžu byť aj riešenia založené na strojovom učení (ML), ktoré by sa natrénovali na historických dátach a odhaľovali anomálie v novopríchodzích.
Záver #
ETL procesy a ich testovanie sú menšinová oblasť IT, ale majú svoje čaro. Postupom času zistíte, kde všade môže nastať problém. Niekoľko takých tipov na čo si dať pozor:
- prehodenie hodnôt medzi dvoma stĺpcami rovnakého dátového typu
- náhle zastavenie dodávania dát od tretej strany
- náhla zmena schémy surových dát
- hodiny dát naviac a menej v dňoch prechodu na letný čas a späť
- uistite sa, že sťahujete naozaj všetky surové dáta z ich zdroja
- uistite sa, že nahrávate naozaj všetky spracované dáta na cieľový systém
- pravidelne zálohujte dáta, môže sa stať, že workflow vymaže/pokazí časť dát
- dobré je aj pravidelne sledovať historické dáta v cieľovom systéme, môže sa stať, že workflow vymaže časť dát, nahrá dáta viackrát alebo prepíše inú partíciu ako má a takto to môžete zistiť
- pozor na upgrady používaných nástrojov. Spark 2.4 zmenil ako sa ukladajú prázdne reťazce z CSV (null/prázdny reťazec), čo malo vplyv na spájanie datasetov na dotknutom stĺpci
- ak beh workflowu prechádza cez polnoc (alebo inú pre Vás relevantnú časovú hranicu), uistite sa, že všetky kroky workflowu pracujú s tými batchmi dát, s ktorými majú
🙏 🙏 🙏
Ak ste sa dostali až sem a príspevok sa Vám páčil, jeho zdieľanie na Vašej obľúbenej sociálnej sieti ma veľmi poteší 💖!
Dátum publikovania: