Zbežný prehľad fungovania Apache Spark
Apache Spark je jedným z najpoužívanejších nástrojov pre analýzu dát vo veľkej škále (big data), rieši situáciu, keď sú dáta také veľké, že ich uloženie a spracovanie nedokáže jeden počítač. Zvláda dávkové (batch) spracovávanie dát, spracovávanie dát v reálnom čase (streaming), interaktívne dotazovanie, výpočty a operácie s grafom a strojové učenie (machine learning).
Ide o open-source framework na spracovanie dát, ktorý dokáže rýchlo vykonávať procesovacie úlohy nad veľmi veľkými množinami dát a tiež dokáže tieto úlohy distribuovať medzi viacero počítačov, ktoré ich paralelne a nezávisle od seba spracúvajú. Pre svoje fungovanie vyžaduje manažér clustera počítačov (napr. Hadoop YARN - Yet Another Resource Negotiator) a distribuovaný systém súborov (napr. HDFS - Hadoop Distributed File System).
Obrázok znázorňuje 4 knižnice pre rôzne účely a programovacie jazyky, ktoré podporuje základné API:
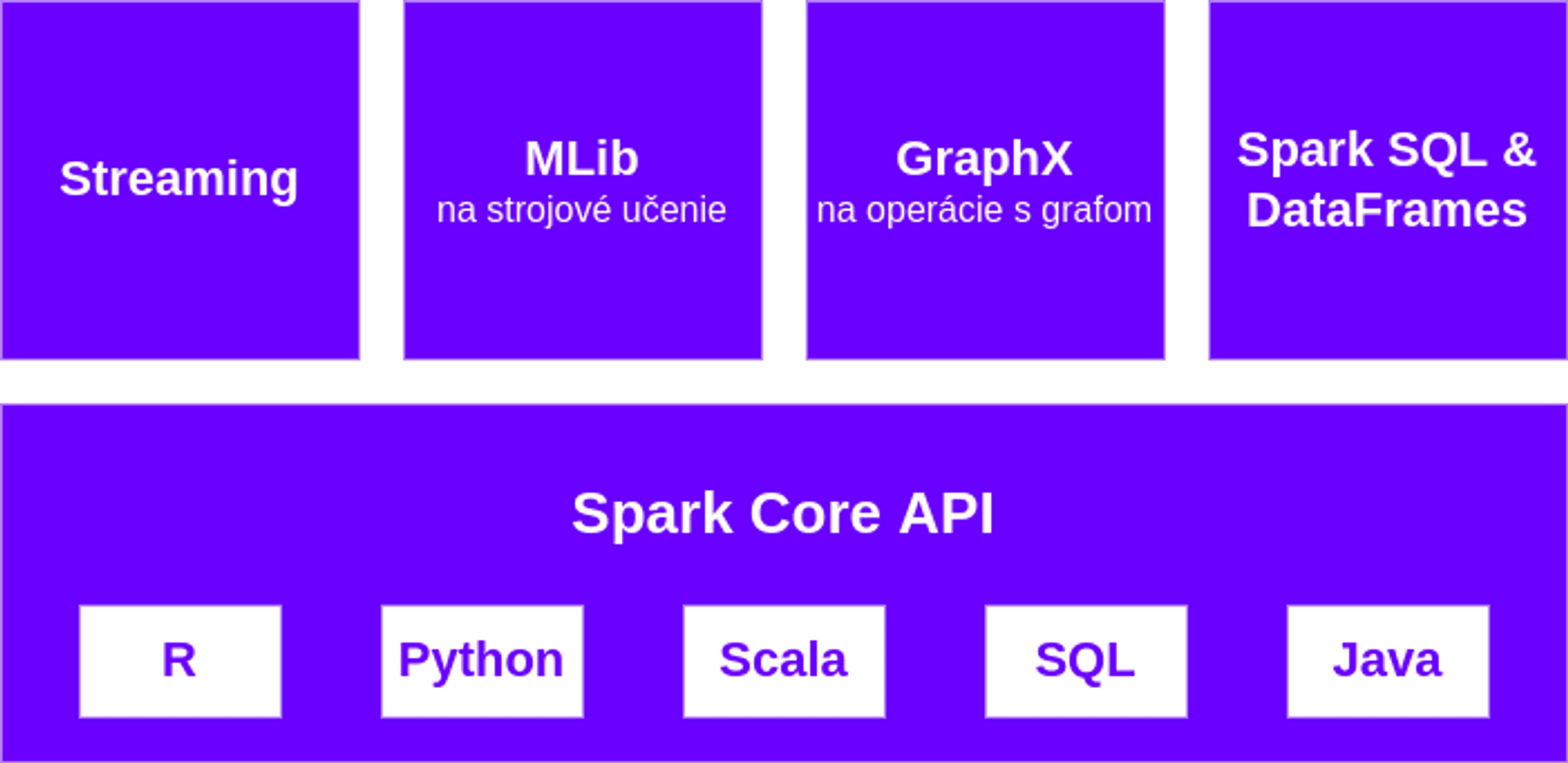
Spark je napísaný v programovacom jazyku Scala, prvá verzia vyšla v roku 2010 (od 2014 pod hlavičkou firmy Apache) a najnovšia verzia je 3.2.1 z januára 2022.
Spočiatku sa Spark využíval na vlastnom "železe" - firmy vlastnili a starali sa o svoje Hadoop clustere, v dnešnej dobe cloudu sa už poskytuje ako manažovaná alebo serverless služba, menovite Amazon EMR, Azure Databricks alebo Spark on Google Cloud, takže používateľom odpadá starosť o manažovanie clustera.
Spark Core #
Je základným kameňom Sparku a ide o rozhranie pre programovanie aplikácií sústredené okolo abstrakcie nazývanej RDD.
Najprv však priblížim 2 procesy, ktoré naštartuje Spark cluster po spustení Spark aplikácie:
- driver je hlavný, riadiaci proces zodpovedný za vytvorenie Spark contextu, preklad kódu Spark aplikácie na logický plán DAG a následne na výpočtové jednotky, úlohy, ktoré sú distribuované medzi pracovné uzly (worker nodes). Taktiež koordinuje rozvrhnutie úloh a orchestráciu na každom exekútore.
- exekútory bežia na pracovných uzloch clustra a sú zodpovedné za výkon im pridelených výpočtových úloh, vrátenie výsledkov driveru a tiež poskytnutie úložiska pre RDD. Medzivýsledky jednotlivých operácií sa držia v distribuovanej pamäti, neukladajú sa na disk (len ak sa nevojdú do RAM), preto sú veľmi rýchle.
Práve pre sprostredkovanie medzi týmito procesmi je potrebná nejaká forma cluster manažéra - okrem spomínaného YARNu sa novšie používa Kubernetes.
Spark RDD #
Resilient Distributed Dataset (RDD) je abstrakcia reprezentujúca nemennú kolekciu objektov, ktorá môže byť rozdistribuovaná medzi výpočtový cluster. Operácie nad RDD sa tiež dajú rozdeliť medzi uzly clustera a sú vykonávané v paralelnom dávkovom procese, čo vedie k rýchlemu a škálovateľnému procesovaniu.
Spark RDD API uvádza niekoľko transformácií a akcií pre manipuláciu s RDD:
- Transformácie RDD vracajú vždy nový RDD a umožňujú vytvoriť závislosti medzi RDD. Každý RDD v reťazi závislostí má funkciu na výpočet svojich dát a smerník na svoj rodičovský RDD. Transformácia RDD je krok v programe hovoriaci Sparku ako získať dáta a čo s nimi robiť.
- Akcie nad RDD vracajú samotný výsledok, hodnotu (napr. reduce, count, collect). Výsledok môže byť uložený na disk, zapísaný do databázy alebo vypísaný do konzoly. RDD sú vyhodnocované odložene (lenivo - lazy evaluation), vyhodnotenie sa nezačne, kým nie je zavolaná nejaká akcia.
Resilient - odolný alebo schopný obnoviť činnosť - znamená, že ak v niektorom kroku procesu operácia/exekútor spadne, nie je to žiaden problém a potrebný RDD sa obnoví zo vstupných dát a danou reťazou závislostí a transformácií. Beh Spark aplikácie môže pokračovať, celkové spracovanie dát nie je ohrozené a je teda odolné voči zlyhaniam.
Prvotný RDD sa vytvorí paralelným načítaním dát do zvláštnych partícií na jednotlivých pracovných uzloch. Takto má každý uzol inú podmnožinu dát - logickú časť veľkej distribuovanej množiny dát. Exekútory obdržia na spracovanie jednu alebo viac partícií. Exekútor vykonáva v danom čase vždy len jednu úlohu pre danú partíciu. Rozhodovanie o počte partícií je hľadanie kompromisu: ak rozdelíme RDD na veľa menších partícií, rozvrhovanie úloh môže zabrať viac času ako samotný výpočet a na druhej strane málo veľkých partícií môže znamenať, že nedôjde k vyťaženiu všetkých pracovných uzlov a nevyužijú sa tak výhody paralelizmu.
RDD môžu byť vytvorené dvomi spôsobmi:
- odkazovaním sa na súbor dát v externom úložnom systéme, ako je zdieľaný súborový systém, HDFS, HBase, jednoduchý textový súbor, SQL databáza, NoSQL sklad (ako Cassandra a MongoDB), bucket na úložisku Amazon S3 a veľa iných,
- paralelizovaním existujúcej kolekcie v programe drivera - aplikovaním transformácií na existujúcich RDD. Okrem tradičnej map and reduce funkcionality má Spark tiež vstavanú podporu pre spájanie data setov, filtrovanie a agregácie.
DAG #
Druhou hlavnou abstrakciou v Sparku je DAG (directed acyclic graph). Spark definuje úlohy, ktoré môžu byť paralelne vypočítané nad partíciami dát v clusteri. Zostrojí logický tok operácií, ktorý je reprezentovaný ako riadený acyklický graf, kde uzly predstavujú RDD partície a hrany transformácie dát.
Logický plán DAGu sa podľa povahy transformácií skonvertuje na fyzický exekučný plán pozostávajúci z etáp (stages). Úlohy v každej etape sa zbalia spolu a pošlú exekútorom. Príklad takého plánu:
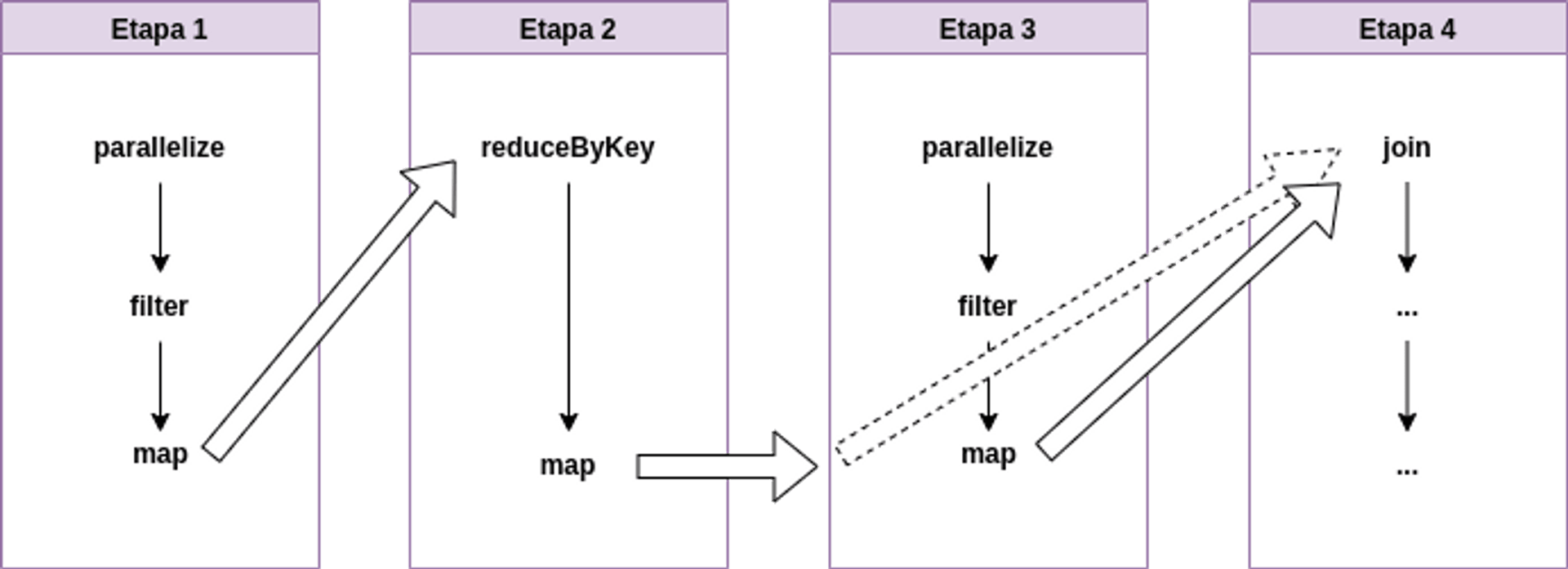
Na etapu 1 nadväzuje etapa 2, etapa 3 je nezávislá na nich a môže bežať paralelne, v etape 4 sa spoja RDD z etáp 2 a 3.
Spark SQL #
Spark SQL priniesol dátovú abstrakciu nazývanú DataFrame, táto poskytuje podporu pre štruktúrované a semištruktúrované dáta (JSON).
DataFrame je distribuovaná kolekcia objektov typu Row organizovaná do pomenovaných stĺpcov, koncepčne zodpovedá tabuľke v relačnej databáze.
DataFramy sú takisto ako RDD nemenné.
Spark SQL poskytuje štandardné rozhranie pre čítanie dát z a zapisovanie do rôznych dátových úložísk vrátane JSON a CSV súborov, Apache Hive, JDBC, Apache Avro, Apache Parquet, existujú aj connectory pre MongoDB atď.
Spark SQL umožňuje dotazovať dáta v rámci Spark aplikácií s použitím DataFrame API alebo SQL dotazov (slúži ako distribuovaný SQL query engine).
Ukážka DataFrame API vs SQL:
spark.read.table("published_mediabi.clicks")
.where(col("dt") === "2020-12-08")
.agg(sum("clicks"))
spark.sql("SELECT SUM(clicks) FROM published_mediabi.clicks WHERE dt = '2020-12-08'")
Spark Shell #
Na rýchle ad-hoc analýzy, prototypovanie a testovanie sa používa Spark shell.
Ak si chcete Spark prakticky vyskúšať na lokálnom počítači, je to možné práve v tejto konzole (stačí mať nainštalovanú Javu), po stiahnutí ju spustíte z rozbaleného adresára príkazom
./bin/spark-shell
- v rámci konzoly funguje automatické dokončovanie pomocou
TAB - pomoc zobrazíme
:help - históriu príkazov
:history - do paste módu pre vloženie viacriadkového kusu kódu sa dostaneme
:paste (a von z neho CTRL+D) - Scala skript môžeme načítať
:load <cesta k súboru> - prácu v konzole ukončíme
:quit
Spark shell pri spustení vytvorí:
- premennú sc pre prístup k SparkContextu (vstupný bod Spark Core funkcionality)
- premennú spark pre prístup k SparkSession (vstupný bod Spark SQL funkcionality)
Príklady načítania dát:
spark.read.parquet("/data/staged/ott/mediabi/googledfp/NetworkImpressions/dt=20201209")
spark.read.option("header", true).csv("/data/staged/media/scv/bluekai_insights_categories/dt=20201209")
spark.read.table("staged_mediabi.dfp_etl_status")
Spustenie príkladov pribalených k inštalácii Sparku a celú dokumentáciu nájdete na https://spark.apache.org/docs/latest/#running-the-examples-and-shell
🙏 🙏 🙏
Ak ste sa dostali až sem a príspevok sa Vám páčil, jeho zdieľanie na Vašej obľúbenej sociálnej sieti ma veľmi poteší 💖!
Dátum publikovania: